Cómo la extensión de multiplicación de RISC-V agrega una multiplicación eficiente de 32 bits al RV32I
La ISA (arquitectura de conjunto de instrucciones) de RISC-V se originó en Berkley en el 2010. Si bien RISC significa núcleo o computación por conjunto de instrucciones reducidas, los fabricantes no pueden resistirse a tomar la ISA de RISC para agregar una instrucción aquí o un nuevo modo de direccionamiento allí, y a completar el mapa de código de operación hasta que se acerque más a la CISC (computación por conjunto de instrucciones complejas) que a la arquitectura RISC. Sin embargo, los desarrolladores de Berkley de RISC-V fueron bastante estrictos a la hora de conservar el núcleo para que fuera un verdadero RISC. La ISA de RISC-V de RV32I se diseñó para tener solo 47 instrucciones básicas (un número extrañamente significativo para los fanáticos tradicionales de Viaje a las estrellas) y, 11 años después, todavía tiene el mismo número.
La filosofía original detrás de mantener un número bajo de instrucciones básicas es que una instrucción CISC compleja se puede reproducir como una serie de instrucciones RISC simples. Según mi experiencia, depende de la aplicación si esto aumenta o no la eficiencia del código y reduce su tamaño. En el pasado, esto ha sido cierto sin lugar a dudas. Tanto es así que Arm agregó instrucciones complejas al mapa de código de operación.
Si bien las instrucciones adicionales pueden ayudar a mejorar el rendimiento, las cosas se complican más cuando tiene un núcleo de 32 bits con instrucciones de 32 bits y luego desea agregar la capacidad de comprimir algunas instrucciones de 32 bits a 16 bits para ahorrar espacio. Sin embargo, para agregar instrucciones de 16 bits, el núcleo debe tener espacio adicional en el mapa de código de operación para estas instrucciones comprimidas, y agregar instrucciones CISC reduce la cantidad de códigos de operación disponibles.
Aquí es donde realmente se destaca la ventaja de RISC-V. Arm agregó más tarde el formato de instrucción comprimida Thumb2 e incorporó estas instrucciones de 16 bits a la ISA existente agregando una ISA separada de 16 bits. Sin embargo, la ISA de RISC-V se diseñó desde el principio con una opción para instrucciones comprimidas y, por lo tanto, tiene solo una ISA. Esto mantiene el núcleo simple y eficiente, y también simplifica el diseño y la prueba de los semiconductores.
Mejora de la ISA de RISC-V RV32I con una instrucción de multiplicación
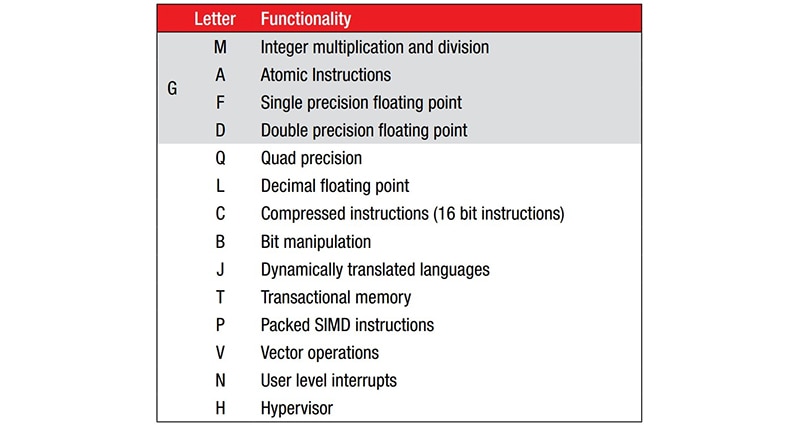
Los fabricantes pueden ampliar la ISA de 47 instrucciones agregando extensiones de instrucción estandarizadas (Figura 1). Como la ISA básica no posee instrucciones para multiplicar o dividir, la extensión M proporciona esa funcionalidad. Por ejemplo, un RV32I con la extensión M se denominaría RV32IM.
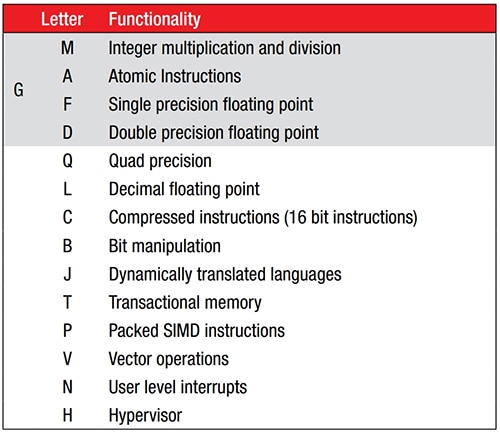 Figura 1: La ISA base de RISC-V de 47 instrucciones se puede expandir agregando extensiones de instrucción estandarizadas, que se indican con un sufijo de letra después del nombre del núcleo. (Fuente de la imagen: RISC-V.org)
Figura 1: La ISA base de RISC-V de 47 instrucciones se puede expandir agregando extensiones de instrucción estandarizadas, que se indican con un sufijo de letra después del nombre del núcleo. (Fuente de la imagen: RISC-V.org)
Un ejemplo de un núcleo con la extensión M es SparkFun Electronics RED-V Thing Plus, con un microcontrolador RISC-V Freedom E310 (FE310) de 32 bits de 150 megahercios (MHz) de código abierto. El núcleo FE310 se designa como RV32IMAC. Además de la capacidad matemática básica de números enteros (I), la referencia a la Figura 1 indica que es compatible con la multiplicación de enteros (M), las instrucciones atómicas (A) y las instrucciones comprimidas (C).
La placa de evaluación RISC-V SparkFun DEV-15799 RED-V (se pronuncia “red cinco”) (Figura 2) tiene 32 megabytes (Mbytes) de memoria flash QSPI de programa y tiene un conector USB-C que se conecta a una computadora host para obtener energía, programación y depuración. También incluye un conector adicional que se puede utilizar para proporcionar energía a la batería.
 Figura 2: La placa SparkFun DEV-15799 se utiliza para evaluar el núcleo FE310 RV32IMAC RISC-V de código abierto de 150 MHz. Se conecta a una computadora host por medio de una interfaz USB-C. (Fuente de la imagen: SparkFun Electronics)
Figura 2: La placa SparkFun DEV-15799 se utiliza para evaluar el núcleo FE310 RV32IMAC RISC-V de código abierto de 150 MHz. Se conecta a una computadora host por medio de una interfaz USB-C. (Fuente de la imagen: SparkFun Electronics)
La extensión M agrega las instrucciones DIV (división con signo) y DIVU (división sin signo) 32/32, así como también las instrucciones REM (restante con signo) y REMU (restante sin signo). También agrega cuatro instrucciones de multiplicación:
- MUL (multiplicación) realiza una multiplicación de registro de 32 x 32 y almacena los 32 bits inferiores del resultado de 64 bits en un registro.
- MULH (multiplicación con signo) y MULHU (multiplicación sin signo) realizan multiplicaciones de registros con signo y sin signo, respectivamente, y almacenan los 32 bits superiores del resultado de 64 bits en un registro.
- MULSHU (multiplicación con signo x sin signo) realiza una multiplicación de registro con signo x sin signo y almacena los 32 bits superiores del resultado de 64 bits en un registro.
Entonces, para una multiplicación sin signo de 32 x 32 = 64, la secuencia de código recomendada es:
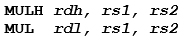
Donde los registros rs1 y rs2 son el multiplicando y el multiplicador, y los registros rdh y rdl son el resultado superior y el inferior de 32 bits, respectivamente.
Al dividir el resultado de la multiplicación de 64 bits en dos operaciones de 32 bits, la ISA no tiene que agregar una instrucción CISC compleja de 32 x 32 = 64. Esto es consistente con la filosofía RISC de usar instrucciones simples para realizar operaciones CISC.
Si bien la mayoría de las instrucciones en la ISA RV32I básica se ejecutan en un solo ciclo de reloj de instrucción, estas instrucciones de multiplicación en la RED-V FE310 requieren cinco ciclos. Según este razonamiento, la secuencia de código recomendada más arriba toma diez ciclos de reloj. Si bien esto puede ser aceptable a 150 MHz, he visto aplicaciones de microcontroladores de muy baja potencia y baja velocidad de reloj donde las interrupciones eran tan críticas que una multiplicación de diez ciclos a 5 MHz es demasiado tiempo para esperar una interrupción crucial. En estos casos, he visto a los desarrolladores de firmware realizar la multiplicación utilizando una subrutina de ensamblaje compleja que se permitió interrumpir.
Sin embargo, el núcleo FE310 tiene la capacidad de tomar instrucciones consecutivas y fusionarlas internamente en una instrucción más rápida a través de la fusión de macrooperaciones. La microarquitectura central puede fusionar las dos instrucciones en una instrucción interna que se ejecuta más rápido que diez ciclos. La microarquitectura RISC-V hace esto automáticamente para algunas secuencias de código, como las cargas indexadas, el par de carga y las instrucciones de par de almacenamiento; lo que mejora significativamente la velocidad de ejecución. Aún mejor, dado que el FE310 admite la extensión C cuando se pueden fusionar dos instrucciones comprimidas de 16 bits compatibles, puede proporcionar ventajas tanto en el código como en la velocidad de ejecución.
Si bien Arm agregó la fusión de macrooperaciones más tarde en sus arquitecturas, al igual que las instrucciones comprimidas, la RISC-V se diseñó con una fusión de macrooperaciones desde el principio. La mejor manera de comprender realmente las ventajas de la compresión de código y cuándo se produce la fusión de macrooperaciones es observar estos comportamientos con una placa de evaluación como la SparkFun DEV-15799. El código se puede examinar en el depurador para ver cómo la microarquitectura FE310 busca y ejecuta cada instrucción. Esto permite una mejor comprensión del comportamiento del lenguaje ensamblador, lo que puede ayudar a escribir códigos eficientes con un compilador C que admita la compresión de código y la fusión de macrooperaciones.
Conclusión
La ISA de RISC-V se enorgullece de presentarse como un conjunto de instrucciones realmente reducidas con solo 47 instrucciones básicas. Esto se puede mejorar con extensiones estandarizadas, como la extensión de multiplicación M que agrega instrucciones de multiplicación y división. La fusión de macrooperaciones, que es inherente a la arquitectura RISC-V, puede acelerar la ejecución de código de instrucciones compatibles, como las instrucciones de multiplicación consecutivas, mientras que la extensión comprimida C reduce el tamaño del código. Tanto las instrucciones comprimidas como la fusión de macrooperaciones le brindan importantes ventajas de rendimiento sobre otras arquitecturas.
Acerca de este autor

Bill Giovino es ingeniero electrónico con un BSEE de la universidad de Syracuse y es uno de los pocos profesionales capaz de pasar de ingeniería en diseño a ingeniería de aplicación en campo a marketing tecnológico de forma exitosa.
Durante más de 25 años, Bill ha disfrutado promocionar las nuevas tecnologías a audiencias técnicas y no técnicas por igual en muchas empresas, entre ellas STMicroelectronics, Intel y Maxim Integrated. Mientras trabajó en STMicroelectronics, Bill ayudó a dirigir los primeros éxitos de la empresa en la industria de microcontroladores. En Infineon, Bill estuvo a cargo de que el diseño del primer controlador de la empresa tuviera éxito en la industria automotriz de EE. UU. Como consultor de marketing para CPU Technologies, Bill ha ayudado a muchas empresas a convertir sus productos con bajo rendimiento en casos de éxito.
Bill fue uno de los primeros en adoptar el Internet de las cosas, incluso colocar la primera pila de TCP/IP en un microcontrolador. Bill es un ferviente creyente de "Vender a través de la educación" y de la gran importancia de contar con comunicaciones claras y bien escritas a la hora de promocionar productos en línea. Es moderador del grupo en Linkedin denominado Semiconductor Sales & Marketing (Marketing y ventas de semiconductores) y habla sobre el concepto B2E (empresa-empleado) de manera fluida.

Have questions or comments? Continue the conversation on TechForum, Digi-Key's online community and technical resource.
Visit TechForumBlogs relacionados

Más blogs de este autor